 (1)")
The ultimate guide to Naive Bayes
In the vast field of machine learning and data science, Naive Bayes is a powerful and widely used algorithm that has proven its effectiveness in various applications. Whether you’re a beginner starting your journey in the realm of data analysis or an experienced practitioner looking to expand your toolkit, this comprehensive guide will walk you through the fundamentals, inner workings, and practical implementations of Naïve Bayes. By the end, you’ll have a solid understanding of how this probabilistic classifier operates, enabling you to leverage its capabilities to make informed decisions and gain valuable insights from your data. So, in this article, we will explore the following:
- What is classification? and when to use classification algorithms?
- What is Bayes’ theorem?
- What is Naive Bayes algorithm?
- When to use Naive Bayes?
- Advantages of using Naive Bayes
- Disadvantages of Naive Bayes
- Naive Bayes Types
- Python implementation
What is classification? and when to use classification algorithms?
- The Classification algorithm is a Supervised Learning technique that is used to identify the category of new observations on the basis of training data.
- In Classification, a program learns from the given dataset or observations and then classifies new observation into a number of classes or groups, such as: Yes or No, 0 or 1, Spam or Not Spam, cat or dog, etc.
- Classes can be called as targets, labels or categories.
- You can also check Types of Machine Learning Systems.
- Classification algorithms can be used when the desired task is to train a model to classify each input into one of 2 or more categories.
- Also, to train such a model it is necessary to have a sufficient amount of labeled data where each sample has its label determining to which class it should belong.
What is Bayes’ theorem?
- In statistics and probability theory, the Bayes’ theorem (also known as the Bayes’ rule) is a mathematical formula used to determine the conditional probability of events.
- Essentially, the Bayes’ theorem describes the probability of an event based on prior knowledge of the conditions that might be relevant to the event.
- The theorem is named after English statistician, Thomas Bayes, who discovered the formula in 1763. It is considered the foundation of the special statistical inference approach called the Bayes’ inference.
- Bayes’ theorem formula is:
P(A|B) = P(B|A)*P(A)/P(B)

What is Naive Bayes algorithm?
- The Naive Bayes consists of two words: 1- Naive: As it assumes the independency between traits or features. 2- Bayes: Based on Bayes’ theorem.
- To use the algorithm: 1-We must convert the presented data set into frequency tables. 2- Then create a probability table by finding the probabilities of certain features. 3- Then use Bayes’ theorem in order to calculate the posterior probability.
- For example, let’s solve the following problem: If the weather is sunny, then the Player should play or not?
- Given the following dataset:

- The first step is to convert our data into frequency tables as follows:
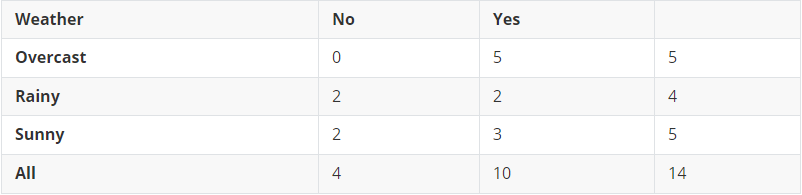
- Then to create the likelihood/probability table as follows:

- Now let’s apply the algorithm to our case:

𝑃(𝑌𝑒𝑠│𝑆𝑢𝑛𝑛𝑦)>𝑃(𝑁𝑜│𝑆𝑢𝑛𝑛𝑦)⇒ So on a sunny day, the player can play the game.
Advantages of using Naive Bayes
- It is one of the fastest and easiest ML algorithms for predicting a class of datasets. It works quickly and can save a lot of time.
- It is suitable for solving multicategory forecasting problems.
- It is used for both binary and multi-class classifications.
- This algorithm performs well in multicategory predictions as compared to some other algorithms.
- It is one of the most common choices for text classification problems.
- When the assumption of feature independence is correct, the algorithm can perform better than other models, it also requires much less training data.
- It is suitable for classification with discrete features that are categorically distributed.
Disadvantages of using Naive Bayes
- It assumes that all predictors (or features) are independent, where this limits the applicability of it in real-world use cases.
- This algorithm has a “zero-frequency problem” that assigns null probabilities to the categorical variables whose classes in the test dataset are not available in the training dataset, a smoothing method can be used in order to overcome this problem.
- Its estimates can be wrong in some cases, so you shouldn’t take its potential outcomes very seriously.
Naive Bayes Types
- Categorical: Used with categorical features, fails when it faces an unknown category.
- Gaussian: Used for Gaussian distributed features.
- Complement: Used for imbalanced data, as it measures the probability of each sample belonging to all other classes not its class.
- Bernoulli: Used when features fellow Bernoulli distribution, it is suitable for discrete data, where it is designed for binary/boolean features.
- Multimodal: Unlike Bernoulli it works with occurrence counts, not only binary features.
Python implementation
- Importing required libraries
import numpy as np
from keras.datasets import mnist
from sklearn.naive_bayes import CategoricalNB, GaussianNB, ComplementNB, BernoulliNB, MultinomialNB
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report- Importing the dataset
(X_train, y_train), (X_test, y_test) = mnist.load_data()- Data reshaping
X_train = X_train.reshape(X_train.shape[0],-1) / 255.0
X_test = X_test.reshape(X_test.shape[0],-1) / 255.0- Model training
classifier = MultinomialNB()
classifier.fit(X_train, y_train)- Model evaluation
y_pred = classifier.predict(X_test)
print(classification_report(y_test,y_pred))- To use a different model type just change the called model type before training using one of the following lines:
classifier = CategoricalNB()
classifier = GaussianNB()
classifier = ComplementNB()
classifier = BernoulliNB()
classifier = MultinomialNB()- Evaluation using the Multinomial NB:
y_pred = classifier.predict(X_test)
print(classification_report(y_test,y_pred))- Results:

Resources & References
- Read more about Classification algorithm.
- Read more about Bayes’ theorem.
- Read more about Naïve Bayes algorithm, also Naïve Bayes.


